Replicação
Embora a ideia de replicação seja simples, isto é, criar cópias de um componente para garantir que algum está sempre disponível para continuar a entregar as funcionalidades do sistema, a implementação pode estar longe de ser trivial, pois para que tenhamos realmente cópias, é preciso que as ações tomadas por um componente sejam também tomadas pelas réplicas. Há várias possibilidades de como replicar, em um grau ou em outro de corretude, cada uma com seus prós e contras.
Uma forma de olhar para este problema é considerar em quais réplicas as operações de modificação de dados podem ser inicialmente executadas, levando à distinção entre sistema com múltiplos ou simplesmente um escritor (do inglês, multi ou single writer ).
Multi-Escritores
Nos sistemas multi-escritores, clientes podem disparar operações de modificações de dados (escritas) e de recuperação de dados (leituras) para qualquer réplica.

Encaminhamento de mensagens
A abordagem mais básica para a replicação consiste em permitir que todas as réplicas aceitem operações dos clientes e fazer com que as réplicas repassem as operações que receberam para as demais. Esta abordagem pode ser implementada com diferentes mecanismos de comunicação, com diferentes resultados. Por exemplo, se implementada com o uso de UDP, todas as réplicas receberão as mesmas operações, exceto por alguma eventualmente perdida. Se em vez disso usarem várias conexões TCP conectando todas as réplicas, desde que as réplicas estejam sempre ativas, todas receberão, em algum momento, todas as operações enviadas pelos clientes.

Mesmo que todas as mensagens sejam entregues, a falta de ordenação no processamento de operações pode levar a estados inconsistentes entre as réplicas. Por exemplo, se dois comandos são enviados, um para esvaziar o conteúdo de um arquivo e o outro pra apagá-lo, o processamento desordenado poderá levar uma réplica a ter um arquivo vazio e a outra a não ter o arquivo.

Anti-entropia
Para corrigir inconsistências, réplicas podem comunicar-se frequentemente identificando e corrigindo divergências em seus dados. Este tipo de protocolo, denominado Anti-Entropia, pode ser implementado com um mecanismo de gossiping e usando relógios vetoriais para concordar nas versões de dados conflitantes a se manter. Usando anti-entropia réplicas podem garantir que, se novas operações cessarem, em algum momento estarão consistentes. O termo em inglês para esta garantia é eventual consistency1 e é como funcionam diversos bancos de dados não relacionais como Cassandra, Redis e Dynamo.

Apesar de levar à consistência entre réplicas, o estado alcançado não necessariamente faz sentido do ponto de vista da aplicação pois pode corresponder, por exemplo, a uma ordenação errada dos comandos emitidos por um dado cliente. Por isso, esta técnica não pode ser aplicada em todas as situações.

Único Escritor
No caso de único escritor, as operações de escrita são direcionadas para uma única réplica e, dependendo dos requisitos de consistência dos clientes, as operações de leitura podem ser direcionadas à mesma réplica ou a quaisquer das réplicas.

Primário/Secundário
Foquemos na raiz do problema que aparentemente é a ordenação das operações. Se cada processo pode receber as mensagens em qualquer ordem, ou seja, cada uma tem uma fila de mensagens independente, então as réplicas podem chegar a estados distintos.

Mas e se tivéssemos uma fila única? No caso da replicação primário/cópia,2 o primário é responsável por lidar com clientes e por informar cópias das modificações de estado, efetivamente mantendo a fila única e impondo uma ordenação de operações que faz sentido, correspondendo à ordem de entrega das mensagens.

Algumas observações são importantes sobre a forma como as operações são repassadas para as réplicas aqui.
Operações x Estado
Outro fator importante é que o primário não necessariamente precisa repassar a operação para réplica, podendo passar algo equivalente. Por exemplo, se a operação é um comando SQL que demanda muito tempo para executar mas que altera poucos dados no banco, então o primário poderia enviar as atualizações para réplicas em vez de lhes exigir que reexecutem o SQL. Por outro lado, um pequeno comando SQL poderia gerar uma grande modificação nos dados e, neste caso, repassar o SQL seria mais econômico em termos de comunicação. A melhor abordagem depende de cada aplicação.
Cópias desatualizadas
Operações que levam a atualizações nos dados devem ser feitas sempre no processo primário, pois, do contrário, este não processaria as operações, podendo levar o primário a virar um gargalo do sistema. Para amenizar esta situação, operações que apenas leiam dados poderiam ser enviadas para as réplicas, em vez de para o primário. Contudo, como o primário primeiro executa a operação antes de repassá-la para as réplicas, há um atraso na execução pelas réplicas, o que quer dizer que as leituras poderiam retornar dados antigos.
Replicação em Cadeia
A replicação em cadeia é uma generalização de primário/cópia em que os processos se organizam em uma sequência para executar operações.

Como na abordagem original, atualizações no sistema são sempre direcionadas ao primário, a cabeça da sequência. Leituras, se absolutamente necessitarem dos dados escritos mais recentemente, também devem ser direcionadas à cabeça. Caso contrário, podem ser direcionadas aos processos na cauda, diminuindo a carga de trabalho na cabeça; quanto mais relaxado for a exigência de "frescor" dos dados, mais para o fim da cauda a requisição pode ser enviada.
Lidando com falhas
Em abordagens baseadas em um primário, um passo essencial é identificar as falhas do processo primário para ativar um backup para que tome seu lugar.
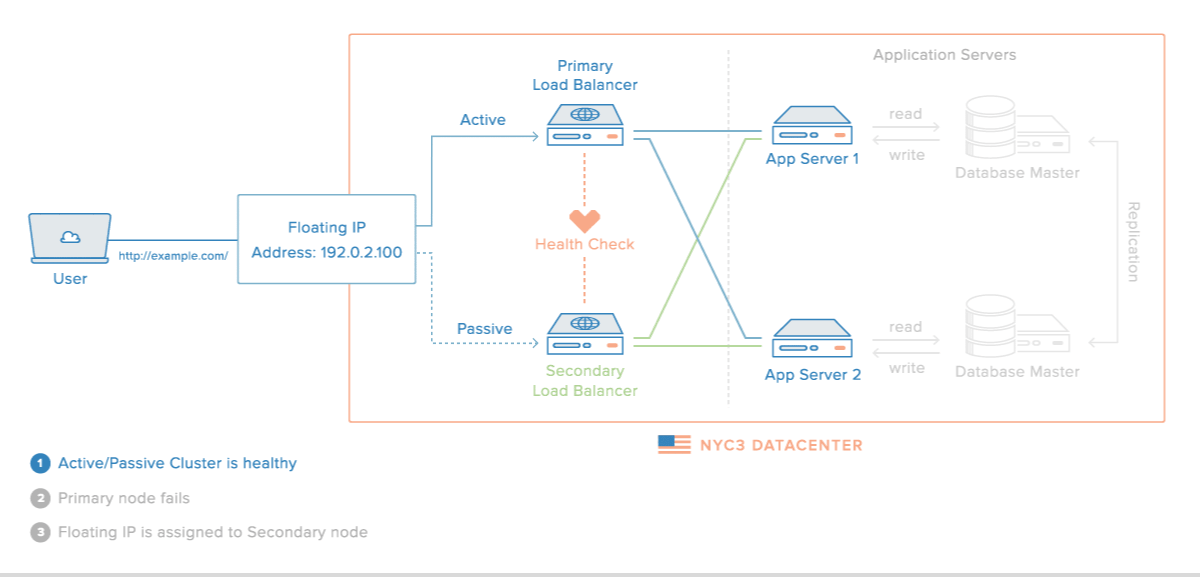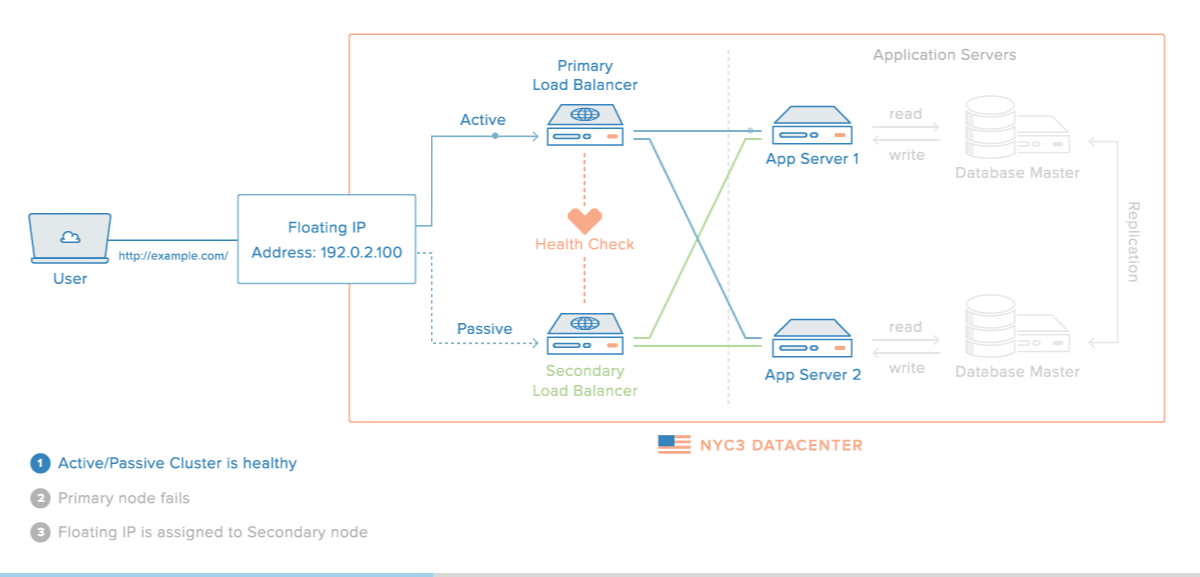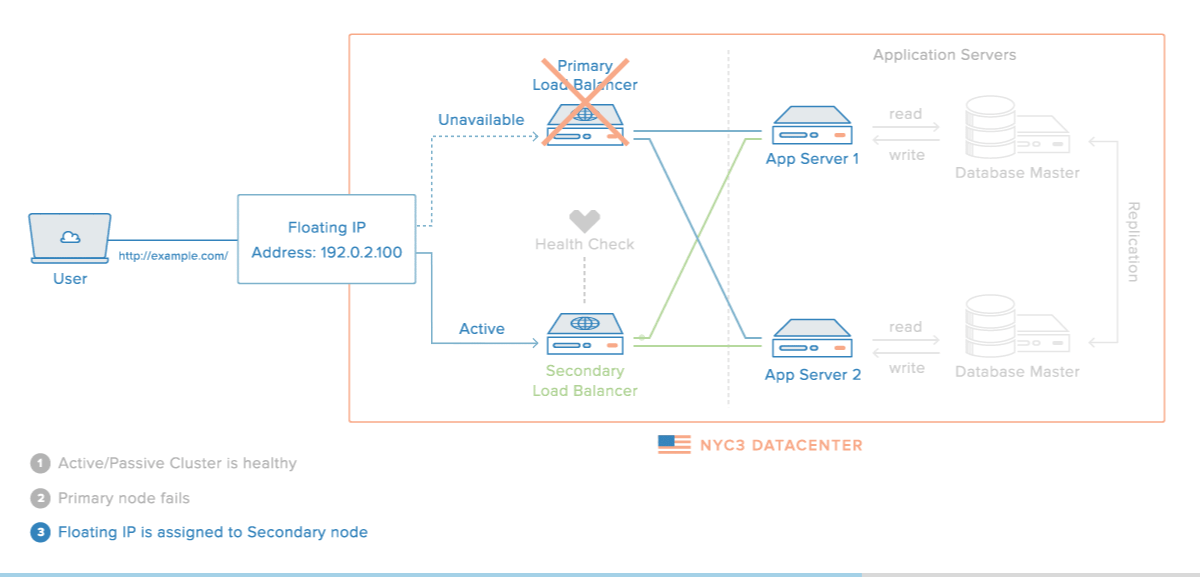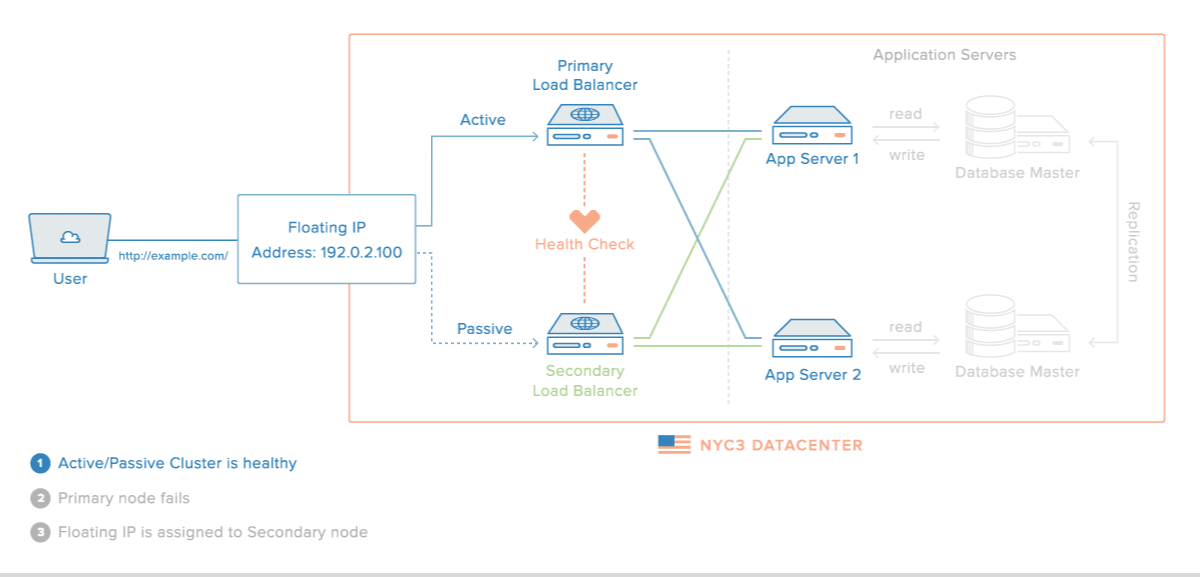
Nesta situação, o primeiro desafio está em identificar a falha. Como já mencionamos e ainda iremos discutir, identificar corretamente a falha de um processo em um ambiente onde a comunicação acontece por troca de mensagens e é assíncrono é impossível, pois não se pode diferenciar um processo falho de um lento.
Mesmo que a identificação fosse perfeita, ainda temos o problema das operações que já foram entregues para o primário mas que ainda não foram propagadas para as réplicas. Quanto o backup assume, ele terá então um estado que está no passado do estado do primário, o que pode levar a comportamento inaceitável. Se este for o caso, replicação ativa pode ser usada.
Replicação ativa
No caso da replicação ativa, as várias cópias executam todos os comandos enviados para o sistema, estando assim todas aptas a continuar a executar o serviço a qualquer instante, pelo menos se as operações de leitura forem enfileiradas também, pois poderiam chegar a uma réplica antes de uma escrita disparada anteriormente.

A técnica de replicação de máquinas de estados, brevemente discutida anteriormente, é uma materialização da replicação ativa. Como vimos anteriormente, replicação de máquinas de estados utiliza primitivas de comunicação em grupo, mas as primitivas vistas anteriormente não são funcionais principalmente por não serem tolerantes a falhas. Vejamos por que é difícil desenvolver primitivas tolerantes a falhas.
Event sourcing
TODO
- Relacionar primitivas de comunicação com filas de mensagem
- Relacionar filas de mensagens com um log
- Relacionar log com event sourcing e stream processing
- Usar time warp como exemplo (Jefferson 1985)
- Usar Kafka como exemplo